Create A New Table
In this step, we'll deploy a few tables to the airlinedb database we've created in the previous steps. As we do this, we will exercise the approval and rejection workflow in SchemaHero to understand how to validate these changes before they are executed.
Airports Table
Let's start by creating a simple table to list airports. Later, our data model will use this when defining routes.
We want a pretty simple table with just 2 columns to define the airport code and the name of the airport.
The SQL that we would have written (before SchemaHero) might look like this:
CREATE TABLE airport
(
code char(4) not null primary key,
name varchar(255)
)
Instead of writing that SQL, let's create this as a SchemaHero table file.
Create a new file named airport-table.yaml and paste the following YAML into it:
apiVersion: schemas.schemahero.io/v1alpha4
kind: Table
metadata:
name: airport
namespace: schemahero-tutorial
spec:
database: airlinedb
name: airport
schema:
postgres:
primaryKey: [code]
columns:
- name: code
type: char(4)
- name: name
type: varchar(255)
constraints:
notNull: true
After saving this file, run kubectl apply -f ./airport-table.yaml to deploy it to SchemaHero.
Let's review this table object:
Lines 1-2: This is the GVK (Group, Version, Kind) of the object.
This should always be set to these same values, however the v1alpha4 may change with future releases of SchemaHero.
Line 4: This is the name of the Table object.
While it's common to set this to the same name as the actual database table, it can be anything.
This does need to conform to Kubernetes naming standards, which includes not using any _ characters.
Line 5: This is the namespace to deploy this Table object to.
This is unrelated to where the Postres database is running, but must match the namespace that we deployed the Database object to in the previous step.
Line 7: This is the name of the Database Kubernetes object that we deployed in the previous step.
You can see the names of available databases by running kubectl get databases -n schemahero-tutorial.
Line 8: This is the actual name of the Postgres table. You can use any supported Postgres characters here.
Line 9: We are defining a table schema.
Line 10: This key indicates that the schema below should be mapped to a Postgres object. SchemaHero supports MySQL and CockroachDB schemas also.
Line 11: We are defining the code column as the primary key.
Note that this is an array object, and composite keys can be defined by listing more than one column.
Primary keys can also be defined in the column definition, if desired.
Line 12: We are defining the columns in this table now.
Lines 13-14: Create a column named code and ensure that it has the char(4) data type.
There are other options here, but we aren't specifying any, so this column will get defaults.
Because this column is the primary key, the column will automatically have a NOT NULL constraint added.
Lines 15-18: Create a column named name and ensure that it has the character varying (255) data type.
We are also adding a NOT NULL constraint to this column to make it a required column.
Validating the migration
Although we've deployed the table object, the schema is not automatically altered.
Instead, a new (or edited) table object will generate a migration object that can be inspected and then approved or rejected.
By default, SchemaHero requires an approval process because some database schema migrations can be destructive.
Immediate deployments (without approval) can be enabled by adding a key to the database object.
To see the pending migration, run:
kubectl schemahero get migrations -n schemahero-tutorial
You should see 1 migration, like this:
ID DATABASE TABLE PLANNED EXECUTED APPROVED REJECTED
eaa36ef airlinedb airport 11s
(Note, if you see No resources found, wait a few seconds and try again. The SchemaHero Operator has to complete the plan phase before the migration is available).
View the migration
Before approving this migration, let's view the generated SQL statement that is attached to the migration object.
Take the ID from the output of the previous command, and run describe migration:
kubectl schemahero describe migration eaa36ef -n schemahero-tutorial
The output will look like this:
Migration Name: eaa36ef
Generated DDL Statement (generated at 2020-06-06T10:41:04-07:00):
create table "airport" ("code" character (4), "name" character varying (255) not null, primary key ("code"));
To apply this migration:
kubectl schemahero -n schemahero-tutorial approve migration eaa36ef
To recalculate this migration against the current schema:
kubectl schemahero -n schemahero-tutorial recalculate migration eaa36ef
To deny and cancel this migration:
kubectl schemahero -n schemahero-tutorial reject migration eaa36ef
Reviewing the SQL
At the top of this output, the Generated DDL statement is the planned migration. This is the exact SQL statement(s) that SchemaHero will run to apply this migration.
Below that, SchemaHero provides 3 commands for the next steps:
apply: Running this command will accept the SQL statement and SchemaHero will execute it against the database.
recalculate: Running this command will instruct SchemaHero to discard the generated SQL statement(s) and generate them again.
This is useful if the database schema has changed and you want SchemaHero to re-execute the plan.
reject: Running this command will reject the migration and not execute it.
Applying the migration
After looking at the generated SQL command, we can see that it's safe and as expected. The next step here is to approve the migration so that SchemaHero will execute the plan.
kubectl schemahero -n schemahero-tutorial approve migration eaa36ef
Running the command will produce:
Migration eaa36ef approved
We can see that SchemaHero has processed this by running get migrations again:
kubectl schemahero get migrations -n schemahero-tutorial
Now, the output looks like:
ID DATABASE TABLE PLANNED EXECUTED APPROVED REJECTED
eaa36ef airlinedb airport 9m38s 38s 52s
This shows that the migration was planned 9 minutes and 38 seconds ago, approved 52 seconds ago, and executed 38 seconds ago.
Verifying the migration
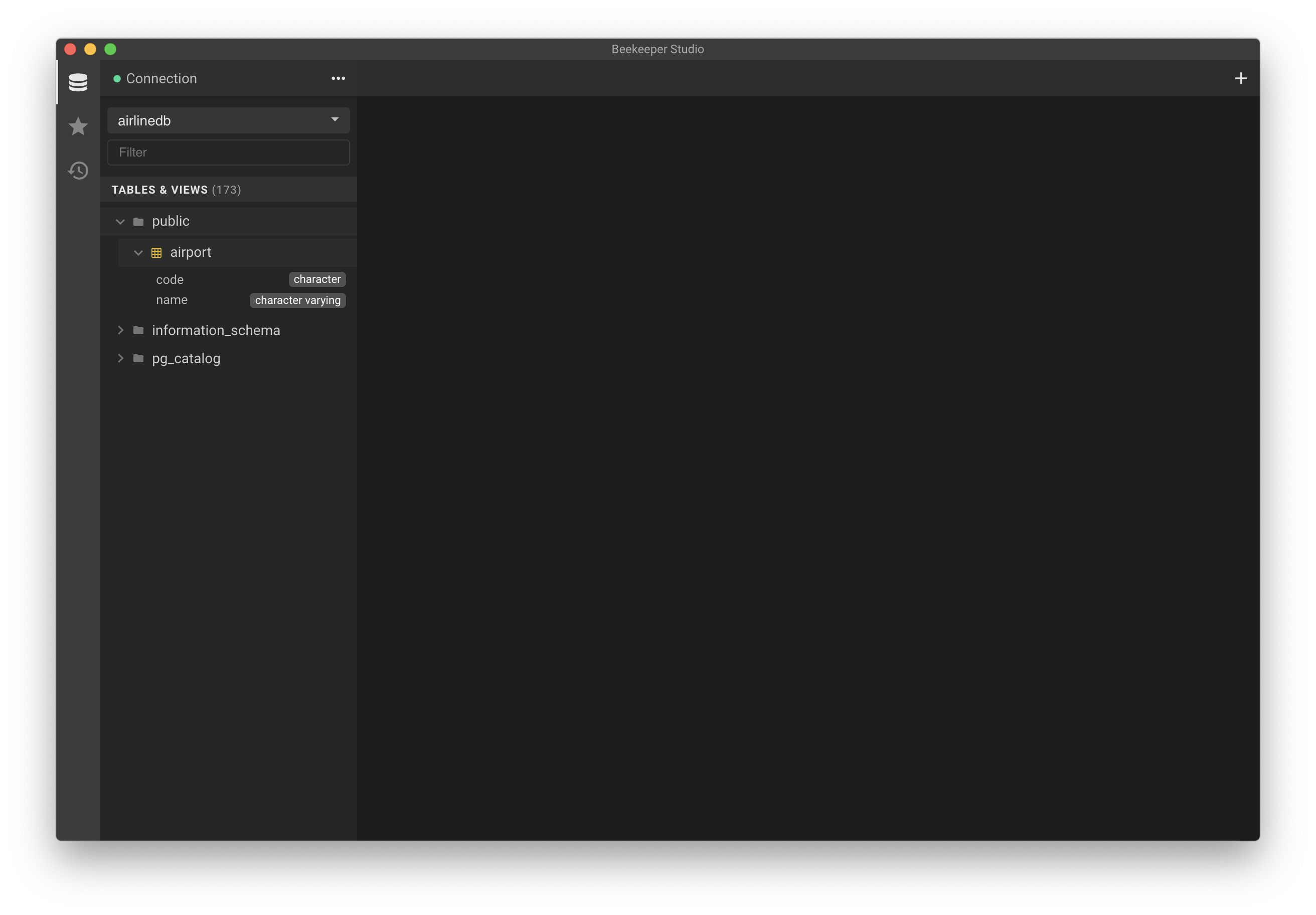
Finally, let's verify this migration in Beekeeper Studio or whatever database management tool you are using.
Clicking Refresh on the "Tables & Views" header in the left nav, we now see the airport table under "public".
Expanding airport and you can see the columns in the table.
Next steps
Next, we will create and deploy a couple of additional tables, but making edits to them after the initial deployment. Continue to the modify a table tutorial.